在处理文本数据时,我们面临一个常见的问题:大小写。在程序看来,EURUSD、EurUsd和eurusd是三个完全不同的东西,这会给我们的比较和筛选带来巨大的麻烦。
为了解决这个问题,我们需要一个标准化工具,能无视原始文本的大小写,强行把它们统一成一种格式。这个工具就是str.lower()函数,它的作用只有一个:把字符串里所有的大写字母,通通转换成小写。
与它功能相反的是str.upper()函数,负责把所有字母都转成大写。
str.lower()函数详解
它的用法极其简单:str.lower(你要转换的字符串)。
函数会返回一个全新的、转换后的小写字符串。有几点要注意:
如果原始字符串里没有字母(比如"43.29"),那么返回的字符串和原始的完全一样。如果你给它一个空字符串""或者na值,它也会返回一个空字符串""。这个函数返回的是一个新的字符串副本,它不会修改你传入的原始字符串变量。
str.lower()这个函数本身只是简单地转为小写,但它的威力在于作为“预处理”步骤,为其他函数服务。这正是我们之前自己动手创建不区分大小写的StrContains()、StrStartsWith()等函数的核心思想:先用str.lower()统一格式,再用其他函数进行比较或处理。
这是一种非常重要和普遍的编程技巧,能大大简化你的逻辑,避免因为大小写问题而出错。
实战案例
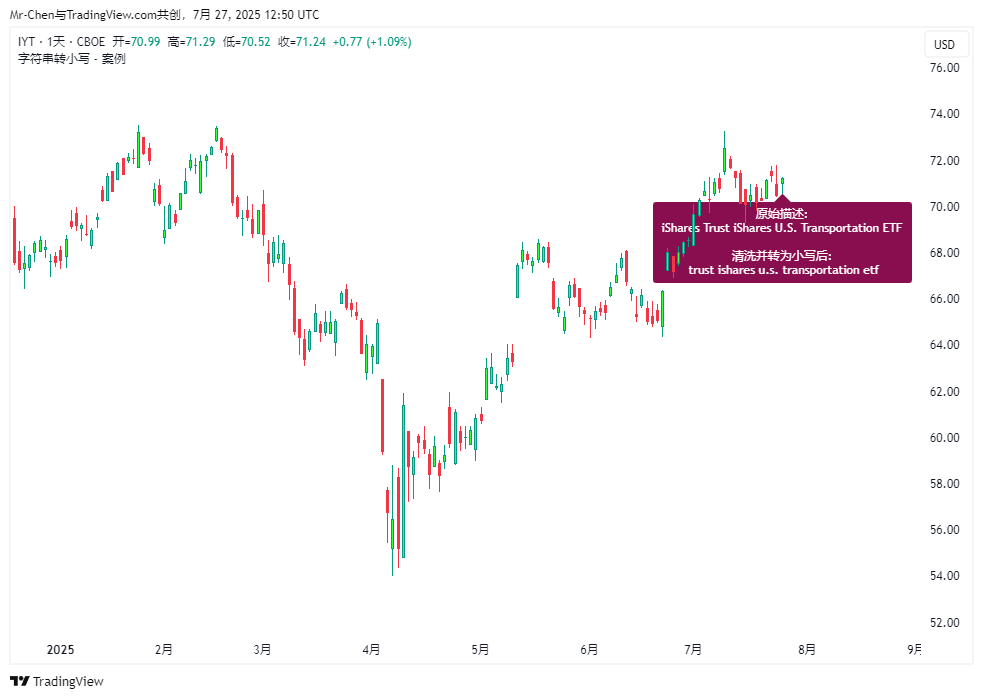
下面的指标完美地展示了“先标准化,再处理”的思路。它的目标是从交易品种的描述中,移除掉“ishares”这个单词,无论它以何种大小写形式出现。
//@version=6
indicator(title="字符串转小写 - 案例", overlay=true)
// 1.先转为小写,在用str.replace()查找并移除 "ishares"
descCleaned = str.replace(str.lower(syminfo.description), "ishares", "")
// 2. 对比结果
if barstate.islastconfirmedhistory
label.new(bar_index, low, style=label.style_label_up,
color=color.maroon, textcolor=color.white,
text="原始描述:\n" + syminfo.description +
"\n\n清洗并转为小写后:\n" + descCleaned)
这段代码的核心在于str.replace(str.lower(syminfo.description), "ishares", "")这一行。程序会先执行最里面的str.lower(),把描述文本“标准化”成全小写,然后再用str.replace()在标准化的文本里,精确地查找并替换掉"ishares"。
在图表上,这个标签会显示当前交易品种的原始描述,以及去掉了“ishares”并转换为小写后的描述。对于 iShares ETF,描述中将不再包含发行人的名称:
总结
总结一下,str.lower()是你文本处理工具箱里最基础、也最重要的“标准化”工具。它的核心价值在于,通过统一大小写,为后续的比较、替换、筛选等操作扫清障碍。记住“先标准化,再处理”这个编程思想,你的字符串处理逻辑会变得更简单、也更可靠。另外,别忘了,它和它的兄弟函数str.upper()都是v5版本才有的新功能。

