用array.mode()获取Pine Script数组的众数
当我们创建了数组并向其中填充了元素后,可以用Pine Script的array.mode()函数返回该数组中元素的众数。所谓众数,指的就是数组中出现频率最高的值。
该函数的标准语法格式如下:
array.mode(id)
id是目标数组的引用,该数组必须是整数或浮点数类型。这个引用通常由创建数组的函数(如array.new_int()或array.new_float())返回,它告诉Pine Script我们要操作的是哪个数组。
array.mode()的返回值有两种可能。一是一个整数或浮点数值,代表数组中出现频率最高的值;有一个特殊情况,当数组中存在多个频率相同的最高频数值时,array.mode()会返回其中数值最小的那个。二是na值,在这几种情况下会返回na:数组是空的(没有任何元素);数组没有众数,这发生在数组中所有数值的出现频率都相同时(例如每个数字都只出现一次);数组中只包含na值。如果数组在包含na值的同时也包含有效数值,array.mode()会自动忽略na值,仅计算有效数值的众数。
快速入门
要获取一个数组中最常见的元素,首先需要一个整数或浮点数类型的数组。如果我们已经创建了这样一个数组,引用存储在myArray变量中,可以像下面这样获取它的众数:
// 获取 'myArray' 数组中最常见的值
dataMode = array.mode(id=myArray)
顺便一提,id=这个关键字参数并非强制要求,示例中使用它主要是为了让代码意图更清晰。你完全可以省略它以减少代码量,像这样也完全正确:
// 获取 'myArray' 数组中最常见的值
dataMode = array.mode(myArray) // 省略了可选的 'id='
array.mode()进阶示例
为了更好地理解array.mode()函数的用法,通过一个详细的示例来逐步拆解。首先,在计算众数之前,需要一个数组:
// 创建一个新的空数组
myArray = array.new_int()
这段代码用array.new_int()创建了一个整数数组,引用存入myArray变量。由于未指定初始大小,数组在创建之初是空的:
[ ]
一个空数组自然没有众数,先向其中添加几个元素:
// 向数组中添加两个值
array.push(id=myArray, value=4)
array.push(id=myArray, value=32)
array.push()函数在数组末尾添加了两个元素。此时数组的内容是:
[4, 32]
现在数组中有了一些值,我们来尝试寻找它的众数:
// 获取数组中最常见的值
dataMode = array.mode(id=myArray)
我们调用array.mode()函数来获取数组中最常见的元素。但由于当前数组中的每个元素(4和32)都只出现了一次,频率相同,所以数组没有唯一的众数。因此,array.mode()返回na:
NaN
为了解决这个问题,再向数组中添加一些元素,创造出一个众数:
// 向数组中添加更多值
array.unshift(id=myArray, value=4)
array.unshift(id=myArray, value=12)
array.unshift(id=myArray, value=-7)
array.unshift()函数在数组的开头添加了新元素。现在,数组的内容变为:
[-7, 12, 4, 4, 32]
再次调用array.mode()获取更新后的众数:
// 获取数组的众数值
dataMode := array.mode(id=myArray)
现在,array.mode()返回了:
4
4在数组中出现了两次,是频率最高的数值,所以它确实是这个数组的众数。
array.mode()的应用场景
array.mode()函数能够返回数组中频率最高的元素值。这个便捷的函数让我们无需手动编写循环来统计频率和寻找众数,大大简化了代码。除了高效地获取众数之外,该函数的功能非常专一,没有其他额外的应用场景。
实战脚本
来看一个使用array.mode()的完整脚本。下面的指标会把图表上每根K线的收盘价都添加到一个数组中,当脚本运行到图表的最后一根K线时,它会找出这个数组的众数。这可以告诉我们在这张图表的整个历史中,哪个收盘价是出现次数最多的。该指标的完整代码如下:
//@version=5
indicator(title="array.mode() example script", overlay=true)
// 创建一个持久性数组,用于存储图表上所有的收盘价
var closePrices = array.new_float()
// 将每根K线的收盘价添加到数组中
array.push(id=closePrices, value=close)
// 在最后一根K线上,通过标签显示最常见的收盘价
if barstate.islast
label.new(x=bar_index, y=high,
color=#FFE4E1, textcolor=color.black, size=size.large,
text="最常见的收盘价:\n" +
str.tostring(array.mode(id=closePrices), "0.00"))
脚本首先用indicator()函数配置基本属性,然后用array.new_float()创建一个浮点数数组。我们用var关键字声明closePrices变量,使其成为一个持久性变量,这意味着该数组只会被创建一次,内容可以在所有K线上累积,而不会被重置。
接着,用array.push()在每根K线上把收盘价close添加到数组末尾。
最后,一个if语句检查当前是否为图表的最后一根K线(barstate.islast)。如果是,就用label.new()创建一个文本标签,背景色为鲑鱼红(#FFE4E1),文本内容显示数组的众数。由于array.mode()返回的是数字,需要用str.tostring()将其转换为字符串,并用”0.00″格式化为保留两位小数的形式。
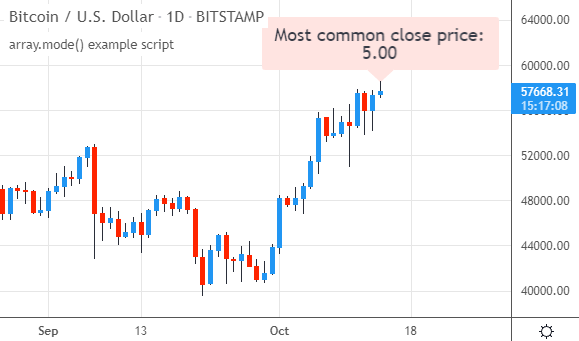
脚本在图表上运行时,会绘制一个标签,显示最频繁出现的收盘价。例如对于比特币(BTCUSD),这个值是很久以前的5.00:
array.mode()的特性
array.mode()只能作用于整数或浮点数类型的数组。如果对其他类型的数组(如颜色或标签数组)调用此函数,Pine Script会生成cannot call ‘array.mode’ with argument ‘id=(…)’. An argument of ‘(…)’ type was used but a ‘float[]’ is expected.的错误。
总结
array.mode()函数返回一个整数或浮点数数组中所有数值的众数(出现最频繁的值)。如果数组是空的、没有众数,或只包含na值,array.mode()将返回na。
用array.range()获取Pine Script数组的极差
在我们创建并填充数组后,可以用Pine Script的array.range()函数返回数组中最大值与最小值之间的差值,也就是范围或极差。
该函数的标准语法是:
array.range(id)
id是你想计算范围的整数或浮点数数组的引用,由创建数组的函数(如array.new_int()或array.new_float())返回。通过它,Pine Script才能知道要对哪个数组进行分析。
array.range()函数的返回值有两种可能:一种是返回一个整数或浮点数,代表数组的最大值与最小值之差;另一种是返回na值,这在数组为空没有任何元素,或者数组中所有元素都是na时会发生。
要注意的是,如果数组中部分元素是na、另一部分是有效数字,array.range()在计算时会忽略所有的na值,只对有效数字计算范围。
快速示例
要获取一个数组的范围,首先需要一个整数或浮点数数组。假设我们已经创建了这样一个数组,引用存储在myArray变量中,可以像这样获取它的范围:
// 从 'myArray' 数组中获取最大值-最小值的范围
dataRange = array.range(id=myArray)
顺便一提,id=这个关键字参数是可选的,省略它代码也能正常工作:
// 从 'myArray' 数组中获取最大值-最小值的范围
dataRange = array.range(myArray)
array.range()分步详解
为了更深入地理解array.range()的运作方式,我们一步步来看。要获取数组的范围,首先需要一个数组,先创建一个:
// 创建一个新的空数组
myArray = array.new_int()
这行代码创建了一个整数数组,引用存入myArray变量。由于未指定大小,这个数组现在是空的:
[ ]
因为对空数组调用array.range()会返回na,所以先用array.push()向数组中添加一些数字:
// 向数组添加值
array.push(id=myArray, value=1)
array.push(id=myArray, value=26)
array.push(id=myArray, value=17)
现在数组的内容变为:
[1, 26, 17]
有了数据,就可以来计算范围了:
// 获取数组的高低范围
dataRange = array.range(id=myArray)
我们调用array.range(),把myArray作为参数传入。函数会计算数组中最大值和最小值的差,并将结果存储在dataRange变量中。结果是:
25
数组的最大值是26,最小值是1,所以范围是25(26 – 1)。
任何改变数组内容的操作都可能影响其范围,要获取更新后的范围,需要再次调用array.range()。用array.unshift()在数组开头添加几个新元素:
// 向数组添加一些更多的新值
array.unshift(id=myArray, value=-34)
array.unshift(id=myArray, value=120)
array.unshift(id=myArray, value=72)
现在数组的内容变为:
[72, 120, -34, 1, 26, 17]
要获取新的范围,再次调用array.range():
// 获取数组更新后的高低范围
dataRange := array.range(id=myArray)
dataRange变量的值现在被更新为:
154
计算过程是120 – (-34) = 154。
array.range()的用途
array.range()函数直接返回数组中最大值与最小值的差。这让我们不必通过array.max() – array.min()的方式手动计算,也避免了编写循环来查找,因此极大地方便了获取数组范围的操作。除了这个核心功能外,array.range()没有其他特殊用途。
示例脚本
通过一个完整的脚本来看看array.range()的实际应用。下面的指标会计算当前K线收盘价与前一根K线收盘价的差值,并将这些差值存入一个数组;当脚本运行到图表的最后一根K线时,它会计算所有这些差值的范围,并用一个文本标签显示出来。指标代码如下:
//@version=5
indicator(title="array.range() 示例脚本", overlay=true)
// 创建一个持久性的浮点数数组,用于存储单K线收盘价变化
var closeChanges = array.new_float()
// 在每根K线上,将收盘价差值添加到数组
array.push(id=closeChanges, value=close - close[1])
// 在最后一根K线上,用标签显示数组的最小-最大范围
if barstate.islast
label.new(x=bar_index, y=close, style=label.style_label_left,
color=#483D8B, textcolor=color.white, size=size.large,
text="单K线收盘价\n变化范围:\n" +
str.tostring(array.range(id=closeChanges)))
解析一下这段代码。脚本先用indicator()进行配置,再用array.new_float()创建一个浮点数数组,var关键字确保该数组是持久的,内容可以在K线之间保留。
在每根K线上,都用array.push()把该K线的收盘价与前一根K线收盘价的差值(close – close[1])添加到closeChanges数组中。然后用if语句和barstate.islast变量确保代码只在图表的最后一根K线上执行一次,并在该K线上用label.new()创建一个指向左方的标签。
标签的文本由两部分组成:一部分是固定的字符串”单K线收盘价\n变化范围:\n”,另一部分是数组的范围——调用array.range(closeChanges)获取范围,再用str.tostring()函数转换为文本,以便在标签上显示。
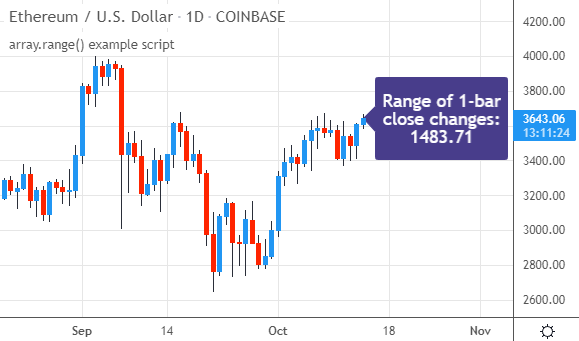
把这个脚本应用到图表时,它会显示出在所加载周期内,单根K线收盘价变化的最大波幅。例如在这个以太坊(ETHUSD)图表上,结果如下:
array.range()的特性
array.range()返回的值在统计学中也称为statistical range(统计范围或极差)。另外,array.range()仅适用于整数数组和浮点数数组,如果对其他类型的数组使用此函数,Pine Script会报错:cannot call ‘array.range’ with argument ‘id=(…)’. An argument of ‘(…)’ type was used but a ‘float[]’ is expected.
总结
array.range()函数返回一个整数或浮点数数组的范围,这个范围是数组中最大值与最小值之差。如果数组为空,或其中只包含na值,array.range()将返回na。


