如何向Pine Script数组的开头添加元素
创建数组之后,可以用array.unshift()函数在数组的开头(头部)添加一个新元素。每次执行这个函数,Pine Script都会把数组的容量增加1,并把新元素插到数组最前面。
该函数的标准语法格式如下:
array.unshift(id, value)
id是要操作的数组的标识符,由创建数组的函数(如array.new_*()系列函数)返回。它告诉Pine Script我们想修改哪个数组——没有这个ID,Pine Script无从知道操作目标。
value是要添加到数组开头的新元素。这个值可以是bool、color、float、int或string等基础类型,也可以是box、label、line、table等特殊对象类型。要注意的一点是,添加的元素类型必须与数组自身定义的类型完全匹配。比如创建了一个整数数组,就只能往里添加整数,不能把颜色值或表格对象塞进整数数组里。
快速入门
array.unshift()函数需要知道修改哪个数组、添加什么值。假设我们之前创建了一个浮点数数组,引用存在myArray变量中,可以像下面这样把新的浮点数值加到数组开头:
// 向 'myArray' 变量所指向的数组开头,
// 分别添加 1.5, 2.5, 和 3.5
array.unshift(id=myArray, value=1.5)
array.unshift(id=myArray, value=2.5)
array.unshift(id=myArray, value=3.5)
注意,id=和value=这类关键字参数是可选的。示例里用它们是为了让代码意图更清晰,并非强制要求。下面的写法同样完全有效:
// 向 'myArray' 数组添加 1.5, 2.5, 和 3.5
array.unshift(myArray, 1.5) // 省略 'id=' 和 'value='
array.unshift(myArray, 2.5)
array.unshift(myArray, 3.5)
array.unshift()进阶示例
那么array.unshift()在实际中是如何工作的?我们一步步来分解。在向数组头部添加元素之前,首先需要一个数组:
// 创建一个用于存储整数的数组
myArray = array.new_int()
这里array.new_int()创建了一个整数数组,返回的数组引用存入myArray变量,方便后续引用。由于没有指定初始大小,数组在创建之初是空的:
[ ]
先向其中添加三个值:
// 向数组中添加三个新值
array.push(id=myArray, value=1)
array.push(id=myArray, value=2)
array.push(id=myArray, value=3)
这里调用了三次array.push()来填充数组,array.push()会在数组的末尾添加新元素。因为依次添加了1、2、3,数组当前的内容是:
[1, 2, 3]
现在,在数组的开头添加一个新元素:
// 在数组开头添加一个值
array.unshift(id=myArray, value=4)
array.unshift()把值4加到了myArray数组的开头。由于数组中已经存在其他元素,这些元素会自动向右平移一个位置,新值4出现在所有原始数字前面:
[4, 1, 2, 3]
再用array.unshift()添加一个元素,看看会发生什么:
// 在数组开头再添加一个值
array.unshift(id=myArray, value=5)
这一次,array.unshift()把值5加到myArray数组的头部,数组变为:
[5, 4, 1, 2, 3]
现在5成了数组的第一个元素(索引为0),所有原有元素再次向右平移一位。这也改变了原有元素的索引:上一步元素4的索引是0,现在随着5的加入,4的索引变成了1。如果脚本此时仍然认为可以在索引0的位置找到4,那可就要出错了。
继续用array.unshift()添加最后一个元素:
// 将又一个值放在所有其他数组元素之前
array.unshift(id=myArray, value=6)
这次添加了值6,Pine Script随之把它插入数组头部:
[6, 5, 4, 1, 2, 3]
注意,我们通过array.unshift()添加元素的顺序是4、5、6,但它们在数组中的最终顺序却是6、5、4,呈现倒序效果。这是因为每一次array.unshift()执行时,新元素总是被插到所有现有元素的前面。
array.unshift()的应用场景
array.unshift()函数的核心用途就是扩大数组并在头部插入新元素。这在需要维护一个后进先出(LIFO)结构、或者希望最新数据排在首位的场景里很有用。除此之外,这个函数的功能非常专一,没有其他复杂的应用场景。
实战脚本
通过一个完整的脚本来看看array.unshift()的实际运作。下面的指标会在每根K线上,把最近3根K线的波幅收集到一个数组中,用array.unshift()添加这些波幅数据。在图表的最后一根K线上,脚本会输出这个数组的内容及其平均值。脚本代码如下:
//@version=5
indicator(title="Basic example of 'array.unshift()'", overlay=true)
// 创建一个用于存储浮点数的数组
barRanges = array.new_float()
// 将最近K线的波幅以倒序方式添加到数组
// (最后添加的元素会排在索引0的位置)
array.unshift(id=barRanges, value=ta.tr[2]) // 前2根K线的波幅
array.unshift(id=barRanges, value=ta.tr[1]) // 前1根K线的波幅
array.unshift(id=barRanges, value=ta.tr) // 当前K线的波幅
// 在最后一根K线上显示数组内容以供验证
if barstate.islast
label.new(x=bar_index, y=high, style=label.style_label_left,
color=color.black, textcolor=color.white, size=size.large,
text="最近3根K线波幅:\n(从新到旧)\n\n" +
str.tostring(barRanges) + "\n\n平均值:\n" +
str.tostring(array.avg(id=barRanges), "0.00"))
首先,indicator()函数配置了脚本的基本属性。然后创建数组:
// 创建一个用于存储浮点数的数组
barRanges = array.new_float()
array.new_float()创建了一个新的浮点数数组。由于没有使用var关键字,这个数组不是持久性的,意味着它在每根K线上都会被重新创建,内容不会继承自前一根K线。
接着填充数组:
// 将最近K线的波幅以倒序方式添加到数组
array.unshift(id=barRanges, value=ta.tr[2])
array.unshift(id=barRanges, value=ta.tr[1])
array.unshift(id=barRanges, value=ta.tr)
我们通过array.unshift()向数组中添加ta.tr(真实波幅)的值。由于array.unshift()每次都把元素加到数组头部,元素在数组中的排列顺序与代码的书写顺序是相反的。代码里先添加了ta.tr[2],再添加ta.tr[1],最后添加ta.tr,数组中的实际内容就变成了[ ta.tr, ta.tr[1], ta.tr[2] ]。
最后在图表上显示结果:
// 在最后一根K线上显示数组内容以供验证
if barstate.islast
label.new(x=bar_index, y=high, style=label.style_label_left,
color=color.black, textcolor=color.white, size=size.large,
text="最近3根K线波幅:\n(从新到旧)\n\n" +
str.tostring(barRanges) + "\n\n平均值:\n" +
str.tostring(array.avg(id=barRanges), "0.00"))
if barstate.islast条件确保这段代码只在图表的最后一根K线上执行。label.new()函数创建了一个文本标签,标签的文本由几部分拼接而成:先是描述性文字,然后通过str.tostring(barRanges)把整个数组转换成字符串显示出来,最后用array.avg()计算数组平均值,并用str.tostring()格式化为保留两位小数的字符串。
脚本在图表上运行时,会绘制一个标签,显示最近3根K线的波幅:第一个元素是当前K线的波幅,第二个是前一根K线的,最后一个是两根K线前的,同时也显示了这三个波幅的平均值:
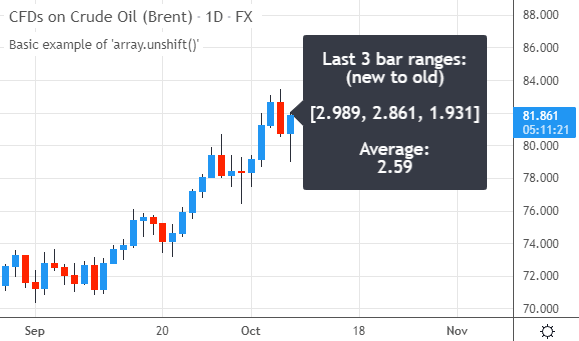
array.unshift()的特性
使用array.unshift()时有几点需要留意。它总是在索引0处添加新元素,所有已存在的元素都会向右平移、索引值加一——如果你的代码逻辑依赖数组中某些元素的固定索引位置,就要特别小心。每次调用时,Pine Script会自动处理数组的扩容、元素平移和新元素插入,我们无需关心底层的内存管理。数组的最大容量为100,000个元素,数组已满时再调用array.unshift()会触发array is too long(数组过长)的运行时错误。另外,由于新元素总是被加到开头,连续用array.unshift()添加的元素在数组中会呈倒序排列,最后添加的元素排在最前;如果希望按时间顺序添加元素(新元素在末尾),应使用array.push()函数。
总结
array.unshift()函数用于在现有数组的开头添加一个新元素,添加的元素类型必须与数组的既定类型相匹配,例如不能向一个颜色数组中添加一条线。它添加新元素时,所有现有元素都会向右平移一位、索引发生变化,这一点需要特别注意。array.unshift()会自动管理数组大小,直至达到100,000个元素的上限。
如何在Pine Script数组的任意位置插入元素
创建数组之后,可以用array.insert()函数在数组的任意内部位置添加新元素。每次调用该函数,Pine Script都会把数组的容量增加1,并在你指定的索引(位置)上插入新元素。
该函数的标准语法是:
array.insert(id, index, value)
id是你想插入新元素的数组的引用,通常由创建数组的函数(如array.new_*()系列函数)返回。有了这个ID,Pine Script才能知道我们要修改的是哪一个数组。
index是一个数字,指定新元素应该插入的目标位置。Pine Script的数组采用从零开始的索引方式:第一个元素的索引是0,第二个是1,第三个是2,以此类推。所以索引值通常是目标位置的序号减1,比如要在第5个元素的位置插入,用的索引是4。
value是要添加到数组中的新元素。这个值可以是bool、color、float、int或string类型,也可以是box、label、line、table等特殊对象。需要注意的是,插入的元素类型必须与数组本身的类型完全匹配。例如创建了一个专门存放box对象的数组,就只能往里添加box对象,不能混入数字或颜色等其他类型。
快速入门
array.insert()的执行需要三个要素:要修改的数组、新元素的插入位置索引,以及新元素的值。假设我们之前创建了一个整数数组,引用储存在myArray变量中,可以像下面这样在数组的第二个元素位置(即索引1)添加新的整数:
// 在索引 1 (即第二个元素的位置) 处,将
// 3, 2, 和 1 这几个值(按此顺序)依次插入到
// ID 存储于 'myArray' 变量的数组中
array.insert(id=myArray, index=1, value=1)
array.insert(id=myArray, index=1, value=2)
array.insert(id=myArray, index=1, value=3)
值得一提的是,id、index和value这些关键字参数是可选的。示例中写出它们是为了让代码意图更清晰,想少敲几下键盘也可以省略。下面的写法同样有效:
// 将 3, 2, 和 1 插入到 'myArray' 数组中
array.insert(myArray, 1, 1) // 省略了 'id=', 'index=', 和 'value='
array.insert(myArray, 1, 2)
array.insert(myArray, 1, 3)
array.insert()分步详解
那么array.insert()的具体工作流程是怎样的?我们一步步来看。在向数组插入元素之前,首先需要一个数组:
// 创建一个空的整数数组
myArray = array.new_int()
这行代码通过array.new_int()创建了一个用于存储整数的数组,函数返回的数组引用保存在myArray变量中,方便后续操作。由于创建时没有提供初始值,此刻数组内容为空:
[ ]
先向数组中添加几个元素:
// 在数组末尾添加元素
array.push(id=myArray, value=1)
array.push(id=myArray, value=2)
array.push(id=myArray, value=3)
array.push()函数每次执行都会在数组的末尾追加一个新元素。这里调用了三次,通过myArray变量指定目标数组,依次添加了1、2和3。此时数组内容变为:
[1, 2, 3]
现在数组里有了元素,可以开始演示插入操作了:
// 在数组中插入一个新值
array.insert(id=myArray, index=2, value=5)
为了在数组内部插入一个元素,我们调用array.insert()并提供三个参数。第一个是myArray变量,告诉Pine Script在哪个数组里操作。第二个参数是2,即新元素的插入位置索引——由于索引从0开始,索引2实际对应数组的第3个位置。最后一个参数是5,就是要插入的新值。
所以array.insert()在这里的操作就是在数组的第三个元素位置上添加数值5,数组变为:
[1, 2, 5, 3]
可以看到,新元素5出现在了索引2(第三个位置)上,原本位于该位置的元素以及后面的所有元素都向右顺移了一位,数组的总大小也增加了1。
再插入一个元素:
// 在数组中再插入一个值
array.insert(id=myArray, index=2, value=10)
我们再次调用array.insert()修改myArray数组,又一次在索引2的位置添加新元素,这次的值是10。来看看数组发生了什么变化:
[1, 2, 10, 5, 3]
和上次一样,新元素10出现在数组的第三个位置,原本在该位置的元素5以及后面的元素3都再次向右顺移。插入一个新元素时,Pine Script可能会更新数组中多个现有元素的位置。
array.insert()可以在任何有效的数组位置插入元素,比如数组的最开始:
// 再向数组中插入一个值
array.insert(id=myArray, index=0, value=15)
这里我们让函数在myArray数组的索引0(第一个位置)添加值15。这会把15放在数组的最前端,所有原有元素向右顺移一位:
[15, 1, 2, 10, 5, 3]
数组大小的限制
array.insert()的作用是在指定索引处添加新元素,这就要求目标索引必须在数组的有效范围内。如果试图在索引8的位置添加元素,但数组本身只有3个元素,代码将无法执行——Pine Script会抛出index is out of bounds(索引越界)的错误。
因此,不要在不存在的数组位置上使用array.insert()。该函数可用的最小索引是0,最大索引等于数组的当前大小。实战中可以用array.size()函数获取数组的大小,确保操作的安全性,也可以通过编写自定义代码来更安全地插入数组元素。
array.insert()的使用场景
array.insert()可以在数组的任意位置添加新元素,这是一个很实用的数组操作,在多种场景下都能派上用场。
不过在某些特定情况下有更简便的选择。虽然array.insert()也能在数组的头部或尾部添加元素,但Pine Script为此专门提供了array.unshift()(头部添加)和array.push()(尾部添加)函数,这两个函数无需指定索引,用起来更直接。
还需注意,array.insert()的功能仅限于插入新元素。如果想替换某个位置上的特定元素,应该使用array.set()函数。
完整示例脚本
通过一个完整的脚本来看看array.insert()的实际应用。下面的指标脚本会把当天交易日的价格数据记录到一个数组中:先把当日的开盘价添加进数组;随后在盘中,每当价格创出新高,array.insert()就把这个新高价存储起来,随着新高不断出现,数组也随之增长;最后脚本在图表上输出数组的最终内容。该指标的完整代码是:
//@version=5
indicator(title="array.insert() 基础示例", overlay=true)
// 创建一个用于存储浮点数的持久性数组
var priceData = array.new_float()
// 创建一个变量,用于追踪当日已出现的最高价
var lastHighPrice = 0.0
// 在每个交易日开始时,清空数组并添加开盘价作为初始值
if dayofmonth != dayofmonth[1]
array.clear(id=priceData)
array.push(id=priceData, value=open)
lastHighPrice := high
// 在盘中,当出现更高的新高时,将该价格
// 插入到数组索引 1 的位置(即第二个元素)
if high > lastHighPrice and array.size(id=priceData) > 0
array.insert(id=priceData, index=1, value=high)
lastHighPrice := high
// 在图表的最后一根 K 线上,输出数组内容
if barstate.islast
label.new(x=bar_index, y=high, color=color.black,
textcolor=color.white, size=size.large,
text=str.tostring(priceData))
脚本以indicator()函数开始,配置指标的基本设置:title为脚本命名,overlay=true让指标直接叠加在主图表上。
接着创建了两个变量:
// 创建一个用于存储浮点数的持久性数组
var priceData = array.new_float()
// 创建一个变量,用于追踪当日已出现的最高价
var lastHighPrice = 0.0
第一个变量priceData用于存储array.new_float()返回的数组引用,我们用这个数组记录全天的价格数据。第二个变量lastHighPrice初始值为0,用于追踪当日的最高价——通过记录这个值,脚本就能判断何时出现了新的日内高点,并只在此时才向数组中添加数据。
这两个变量都用var关键字声明,这能让它们的值在K线之间保持不变(即持久化)。对数组而言,这意味着它包含的元素可以跨K线周期保留,不会在每根新K线上被重新创建。
接下来,在新交易日开始时把开盘价存入数组:
// 在每个交易日开始时,清空数组并添加开盘价作为初始值
if dayofmonth != dayofmonth[1]
array.clear(id=priceData)
array.push(id=priceData, value=open)
lastHighPrice := high
这个if语句通过比较当前K线的月份日期(dayofmonth)与上一根K线是否相同,来判断新的一天是否开始。当新的一天开始时,先调用array.clear()清空数组,移除前一交易日的数据;然后用array.push()把当前K线的开盘价(open)添加到数组中——由于数组刚被清空,此时它只包含这一个元素。为了后续能正确记录新的日内高点,同时把lastHighPrice变量重置为当前开盘K线的最高价(high)。
随后,判断是否出现了新的日内高点:
// 在盘中,当出现更高的新高时,将该价格
// 插入到数组索引 1 的位置(即第二个元素)
if high > lastHighPrice and array.size(id=priceData) > 0
array.insert(id=priceData, index=1, value=high)
lastHighPrice := high
这个if语句有两个条件。第一,检查当前K线的最高价(high)是否超过了已记录的最高价(lastHighPrice),确保只在创出新高时才行动。第二,检查数组的大小(array.size())是否大于零,避免在空数组或不存在的索引上执行插入操作引发错误。
两个条件都满足时,先调用array.insert()向数组插入一个新元素:通过priceData指定目标数组,通过索引1把新元素放在数组的第二个位置(紧跟在开盘价之后),插入的值是当前K线的最高价(high)。最后把lastHighPrice变量更新为当前的最高价,这样下一次if语句就只会在价格创出更高的新高时才执行。
脚本的最后一部分是创建一个文本标签来显示结果:
// 在图表的最后一根 K 线上,输出数组内容
if barstate.islast
label.new(x=bar_index, y=high, color=color.black,
textcolor=color.white, size=size.large,
text=str.tostring(priceData))
这个if语句通过检查barstate.islast变量是否为true,判断当前K线是否为图表上的最后一根。如果是,就调用label.new()创建一个文本标签。标签显示在最后一根K线的最高价位置(bar_index,high),背景为黑色(color.black),文字为白色(color.white),使用大号字体(size.large)。
标签显示的文本是数组的全部内容,用str.tostring()把priceData数组转换为文本字符串,以满足label.new()对text参数的要求。
脚本在图表上运行时,数组中会包含多个值。第一个元素始终是当天的开盘价,其后是当天出现的所有新高,但顺序是倒置的:显示在最前面的高点是当天最后一次创下的新高,而数组中最后的高点值反而是当天出现的第一个新高:
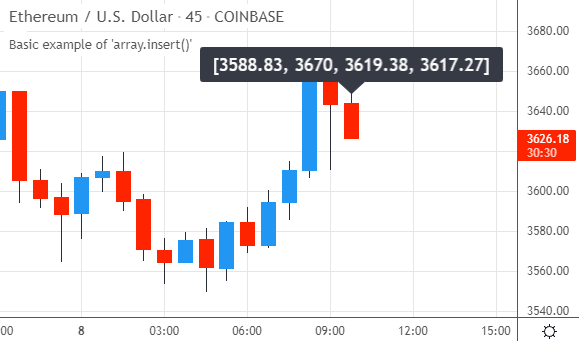
array.insert()的特性
当array.insert()在某个索引处添加元素时,该位置及之后的所有现有元素都会向右移动。如果代码逻辑依赖特定元素固定的索引位置,array.insert()操作就会影响这些逻辑,需要相应更新代码中使用的索引。
脚本每次执行array.insert(),Pine Script都会自动完成三件事:数组大小加1,指定索引及之后的所有元素向右顺移一位,然后在新空出的位置上插入元素。整个过程是自动的,我们无需担心数组的大小或容量管理。
不过,数组的元素数量存在上限,即100,000个。数组达到上限后再调用array.insert()尝试添加元素,TradingView会产生array is too long(数组过长)的错误。
总结
array.insert()函数用于在现有数组的指定位置插入一个新元素,插入的元素类型必须与数组本身的类型相匹配,例如不能把一个布尔值(true/false)添加到整数数组中。插入新元素后,该位置及之后的所有现有元素都会向右顺移一位,可能影响依赖固定索引位置的代码逻辑。另外,插入索引值不能小于零,也不能大于数组的当前大小。
如何避免数组插入时的索引越界错误
Pine Script的array.insert()函数允许我们在数组的指定索引位置添加一个新元素。例如通过这个函数,可以在第5个元素的位置插入一个新值,所有现有的元素会向右顺移一位。
然而,array.insert()的正确使用有一个前提:必须提供一个有效的索引。如果索引值超出了数组的范围(小于0或大于数组的当前大小),就会触发index … is out of bounds, array size is …(索引越界)的运行时错误。
在实际编程中,插入位置的索引常常是通过计算得出的,这就有可能产生一个无效的索引值。我们该如何处理这种情况,避免脚本因错误而中断呢?
自定义安全插入函数
下面这个自定义函数,可以让我们安全地向数组中插入新元素,即使提供的索引是无效的:
// InsertArraySafe() 函数能够以一种安全的方式,将指定值添加到
// 给定数组的指定索引位置。它能确保索引值始终落在数组的有效
// 范围内,从而避免‘索引越界’的运行时错误。
InsertArraySafe(array, index, value) =>
safeIndex = math.min(math.max(index, 0), array.size(array))
array.insert(array, safeIndex, value)
这个名为InsertArraySafe()的自定义函数接收三个参数:array指定要修改的目标数组;index是期望插入新元素的目标索引(从0开始);value则是要插入的新值。
函数的核心逻辑分两步:先计算出一个绝对安全的索引值存入safeIndex变量,再用这个安全索引调用原生的array.insert()完成插入操作。
安全索引的计算巧妙地运用了math.min()和math.max()函数。由于math.max()位于最内层,Pine Script会首先执行它。math.max(index, 0)的作用是返回index和0中较大的那个值,这就处理了负数索引的情况——当index为负数时,math.max()返回0,索引值就绝不可能是负数,从而规避了负数索引导致的越界错误。例如传入的index是-2,math.max()会将其修正为0,新元素被添加到数组的开头,而不是触发错误。
接下来,外层的math.min()函数取上一步结果(修正后的索引)和当前数组大小(array.size(array))中较小的那个值,确保索引不会超出数组的上限。例如数组当前有8个元素,而传入的index是12,math.min()会把索引修正为8,新元素被添加到数组末尾(这是array.insert在索引等于数组大小时的行为),而不是产生错误。
总结一下:math.max()负责守护索引的下限(不小于0),math.min()负责守护上限(不大于数组大小),这一组合把索引值钳制在了绝对安全的范围内。当然,如果传入的index本身就是有效值,经过这两层函数处理后,safeIndex的值保持不变。
最后,用这个万无一失的safeIndex调用array.insert(),把value插入到array中,整个过程安全无虞。要使用这个函数,可以像下面这样调用:
// 将值 12.5 添加到浮点数数组的第5个位置
// (索引为 4)
InsertArraySafe(myFloatArray, 4, 12.5)
// 将红色插入到颜色数组的索引9处
InsertArraySafe(myColorArray, 9, color.red)
注意事项
这个自定义函数的一个特点是,无论你提供的索引多么离谱,它总会把新元素添加到数组里。背后的设计思路是:确保添加这个动作本身能够完成最重要。但这个假设未必适用于你所有的脚本逻辑。
另一种可行的思路是:先检查给定的索引是否有效,只有当索引在数组的合法范围内时才执行插入操作,否则什么也不做。这种方法同样能避免索引越界的错误,但它不会在任何情况下都强制添加新元素。
完整示例脚本
通过一个完整的脚本来看看InsertArraySafe()函数的实际效果。下面的指标创建了一个输入选项,让用户可以指定新元素的插入索引。无论用户输入什么值,我们都通过InsertArraySafe()函数安全地执行插入,不会引发错误。指标的完整代码如下:
//@version=5
indicator(title="Safe use of 'array.insert()'", overlay=true)
// InsertArraySafe() 函数能够以一种安全的方式,将指定值添加到
// 给定数组的指定索引位置。它能确保索引值始终落在数组的有效
// 范围内,从而避免‘索引越界’的运行时错误。
InsertArraySafe(array, index, value) =>
safeIndex = math.min(math.max(index, 0), array.size(array))
array.insert(array, safeIndex, value)
// 创建一个输入选项,用于配置数组的插入索引
insertIndex = input.int(title="数组插入索引", defval=2)
// 创建一个包含5个元素的整数数组,初始值均为0
myArray = array.new_int(size=5, initial_value=0)
// 在用户指定的索引位置插入一个新值 '5'
InsertArraySafe(myArray, insertIndex, 5)
// 在图表上显示结果以供验证
if barstate.islast
label.new(x=bar_index, y=close, style=label.style_label_left,
color=#E6E6FA, textcolor=color.black, size=size.large,
text="数组插入索引: " + str.tostring(insertIndex) +
"\n" + str.tostring(myArray))
脚本首先用indicator()函数进行基本配置,然后包含了前面讨论过的InsertArraySafe()自定义函数。
接下来,创建一个输入选项:
// 创建一个输入选项,用于配置数组的插入索引
insertIndex = input.int(title="数组插入索引", defval=2)
这里input.int()创建了一个整数输入框,标题为数组插入索引,默认值为2,用insertIndex变量接收用户的输入值。
然后,创建一个数组:
// 创建一个包含5个元素的整数数组,初始值均为0
myArray = array.new_int(size=5, initial_value=0)
array.new_int()创建了一个整数数组,初始大小为5,所有元素的初始值都为0。
接着,在数组中插入一个新值:
// 在用户指定的索引位置插入一个新值 '5'
InsertArraySafe(myArray, insertIndex, 5)
我们调用InsertArraySafe()函数,传入三个必要的参数:目标数组myArray,插入索引(来自用户输入的insertIndex),以及要插入的值5。
最后,创建一个标签来显示数组的内容:
// 在图表上显示结果以供验证
if barstate.islast
label.new(x=bar_index, y=close, style=label.style_label_left,
color=#E6E6FA, textcolor=color.black, size=size.large,
text="数组插入索引: " + str.tostring(insertIndex) +
"\n" + str.tostring(myArray))
这段代码仅在图表的最后一根K线上执行。它创建了一个标签,背景色为淡紫色(#E6E6FA),文本内容显示用户当前设定的插入索引,以及执行插入操作后数组的最终内容。
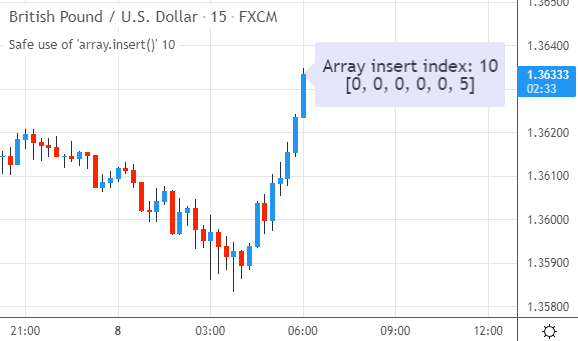
来看看脚本的运行效果。当输入框使用默认值2时,元素5被添加到了数组的第3个位置(索引为2):
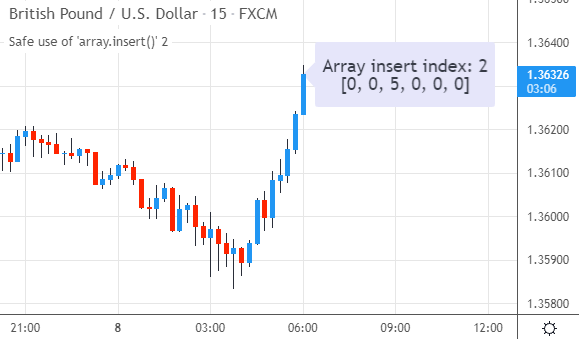
如果把输入值改为负数(例如-5),这通常会引发错误。但得益于InsertArraySafe()函数,元素5被安全地添加到了数组的开头(索引0):
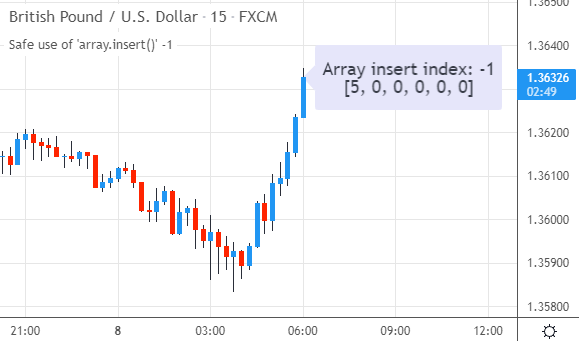
类似地,如果输入一个远超数组大小的索引(例如10),InsertArraySafe()同样能从容应对,把新元素添加到数组的末尾:
更易读的替代方案
上面那个一行代码实现的函数虽然精炼,但对初学者来说可能不易理解。下面是功能完全相同、逻辑更清晰的替代版本:
// InsertArraySafe() 通过验证索引,以安全的方式将指定值添加到
// 给定数组的指定索引位置,避免‘索引越界’的运行时错误。
InsertArraySafe(array, index, value) =>
// 如果索引为负数,则将值添加到数组开头
if index < 0
array.unshift(array, value)
// 如果索引超出数组上限,则将值添加到数组末尾
else if index > array.size(array)
array.push(array, value)
// 如果索引有效,则执行常规插入
else
array.insert(array, index, value)
这个版本的函数通过一个级联的if语句处理不同情况。首先判断index是否小于0,如果是,说明索引无效,此时调用array.unshift()把新元素添加到数组的开头。如果索引不是负数,则进入下一个判断,检查index是否大于数组的当前大小,如果是,同样是无效索引,此时调用array.push()把元素添加到数组的末尾。如果以上两个条件都不满足,说明index是一个在[0, array.size(array)]范围内的有效值,就可以安全地调用原生的array.insert()执行插入操作。
无论传入的index是什么,这个函数都能确保value被无错误地添加到数组中。它的使用方式与前一个版本完全相同:
// 将值 3 添加到索引 12 的位置
InsertArraySafe(myArray, 12, 3)
总结
当array.insert()函数使用了无效索引(小于0或大于数组当前大小)时,Pine Script会触发运行时错误。本文介绍的InsertArraySafe()自定义函数可以自动校正无效的数组索引,从而把数组插入操作变为一个绝对安全的过程。


