用array.standardize()标准化Pine Script数组
当我们创建了数组并向其中填充了元素后,可以用array.standardize()函数接收一个原始数组,并返回一个包含其标准化元素的新数组。
该函数的标准语法格式如下:
array.standardize(id)
id是我们想标准化的目标数组的引用,该数组必须是整数或浮点数类型。这个引用通常由创建数组的函数(如array.new_int()或array.new_float())返回,通过它告诉Pine Script要操作哪个数组。
array.standardize()的返回值有三种可能的情况。一是一个包含标准化后浮点数值的新数组。二是一个空数组,如果原始数组本身就是空的。三是一个特殊处理后的数组,这发生在原始数组只包含na值时——此时函数会返回一个新数组,其中原始数组的每个na元素都对应一个1,例如[na, na, na]经过处理后会变成[1, 1, 1]。要注意的是,如果原始数组是数字和na值的混合体,array.standardize()则会仅对数字进行标准化,并在新数组的相应位置保留na值,例如[1, na, 2, 3, na]会变成[-1.22, na, 0, 1.22, na]。
快速入门
要对一个数组进行标准化,首先需要一个整数或浮点数类型的数组。假设我们已经创建了这样一个数组,引用存储在myArray变量中,可以像下面这样获取它的标准化数组:
// 从 'myArray' 数组获取其标准化版本
dataStandardized = array.standardize(id=myArray)
顺便一提,id=这个关键字参数并非强制要求,示例中使用它主要是为了让代码意图更清晰。你完全可以省略它以减少代码量,像这样也完全正确:
// 从 'myArray' 数组获取其标准化版本
dataStandardized = array.standardize(myArray) // 省略了可选的 'id='
array.standardize()进阶示例
为了更好地理解array.standardize()的具体作用,通过一个详细的示例来逐步拆解。首先,需要一个可供标准化的数组,先创建一个:
// 创建一个新的整数数组
myArray = array.new_int(size=2, initial_value=5)
这里用array.new_int()创建了一个整数数组,引用存入myArray变量。该数组初始包含2个元素,且每个元素的值都是5。所以,数组的初始内容是:
[5, 5]
要标准化这个数组,调用array.standardize()函数:
// 标准化原始数组
dataStandardized = array.standardize(id=myArray)
这段代码创建了一个新变量dataStandardized,用于存储返回的标准化数组。因为myArray数组中的所有元素值都相同(5),它们的标准差为0。在这种特殊情况下,标准化后的值为:
[1, 1]
向数组中添加更多不同的值,看看会发生什么变化:
// 向数组中添加更多值
array.push(id=myArray, value=2)
array.push(id=myArray, value=11)
array.push()函数在数组末尾添加了两个新元素。现在,原始数组的内容更新为:
[5, 5, 2, 11]
每当数组的元素发生变化,都需要重新调用array.standardize()来获取最新的标准化数组。再次执行该函数:
// 标准化更新后的数组
dataStandardized := array.standardize(id=myArray)
我们把返回的新标准化数组再次赋值给dataStandardized变量。现在,这个标准化数组包含的元素如下:
[-0.2294157339, -0.2294157339, -1.1470786694, 1.6059101371]
array.standardize()的应用场景
array.standardize()函数能够从一个整数或浮点数数组返回其标准化版本。这个功能非常有用,让我们无需手动编写循环来为每个元素计算其偏离均值的标准差单位数,不仅节省了编程工作,也更高效。
在数据分析中,我们可能希望把array.standardize()与其他数组统计函数(如array.avg()和array.stdev())结合使用,以更全面地理解数组内数据的分布特性。除了标准化数组这个核心功能外,该函数没有其他额外的应用场景。
实战脚本
来看一个使用array.standardize()的完整脚本。下面的指标会创建一个包含最近3根K线平均价的数组,在图表的最后一根K线上,脚本会创建一个标签,同时显示原始数组和标准化后的数组。该指标的完整代码如下:
//@version=5
indicator(title="array.standardize() example script", overlay=true)
// 创建一个数组,用于存储近期的K线平均价格
averagePrices = array.new_float()
// 将OHLC均价添加到数组中
array.push(id=averagePrices, value=ohlc4)
array.push(id=averagePrices, value=ohlc4[1])
array.push(id=averagePrices, value=ohlc4[2])
// 在最后一根K线上,输出数组的当前元素及其标准化版本
if barstate.islast
label.new(x=bar_index, y=close, style=label.style_label_left,
color=#FFE4C4, textcolor=color.black, size=size.large,
text="原始数组:\n" + str.tostring(averagePrices) +
"\n标准化数组:\n" +
str.tostring(array.standardize(id=averagePrices)))
首先,indicator()函数配置了脚本的基本属性。然后,array.new_float()创建了一个浮点数数组,引用存入averagePrices变量。顺便一提,由于没有使用var关键字,这个数组会在每根K线上被重新创建,因此它不会记录之前K线上的数据。
我们调用三次array.push()来填充数组,把当前K线、前一根K线及再前一根K线的ohlc4值(即开、高、低、收四个价格的平均值)添加到数组中。
接着,一个if语句检查当前是否为图表的最后一根K线(barstate.islast)。如果是,就用label.new()创建一个文本标签,背景色为淡橙色(#FFE4C4),文字为黑色。
标签的文本内容由两部分组成:原始的averagePrices数组内容,以及对其调用array.standardize()后得到的标准化数组内容。由于标签只接受文本,必须用str.tostring()函数把两个数组都转换为字符串格式。
脚本在图表上运行时,标签会显示最近3个OHLC均价以及它们标准化后的值:
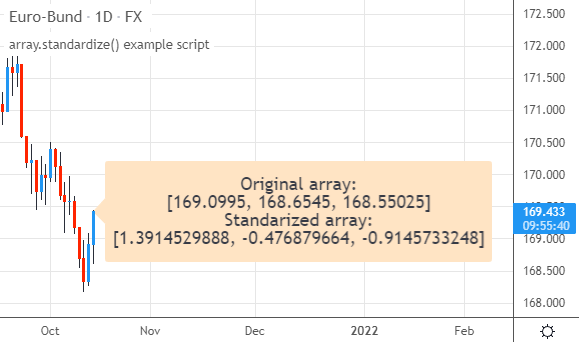
array.standardize()的特性
array.standardize()只能作用于整数或浮点数类型的数组。如果对其他类型的数组(如表格或盒子数组)使用此函数,Pine Script会生成cannot call ‘array.standardize’ with argument ‘id=(…)’. An argument of ‘(…)’ type was used but a ‘float[]’ is expected.的错误。
总结
array.standardize()函数接收一个整数或浮点数数组,并返回一个包含其标准化元素的新数组。如果给定的原始数组是空的,返回的新数组也是空的;如果原始数组只包含na值,array.standardize()会返回一个新数组,其中每个na元素都对应一个1。
用array.stdev()获取Pine Script数组的标准差
在我们创建并填充数组后,可以用Pine Script的array.stdev()函数计算数组中所有元素的标准差。
该函数的标准语法是:
array.stdev(id)
id是你想计算标准差的整数或浮点数数组的引用,由创建数组的函数(如array.new_int()或array.new_float())返回。通过它,Pine Script才能知道要对哪个数组进行操作。
array.stdev()函数的返回值有两种可能:一种是返回一个整数或浮点数,代表数组元素的标准差;另一种是返回na值,这在数组为空没有任何元素,或者数组中所有元素都是na时会发生。
要注意的是,如果数组中部分元素是na、另一部分是有效数字,array.stdev()在计算时会忽略所有的na值,只对有效数字计算标准差。
快速示例
要获取一个数组的标准差,首先需要一个整数或浮点数数组。假设我们已经创建了这样一个数组,引用存储在myArray变量中,可以像这样获取它的标准差:
// 获取 'myArray' 数组的标准差
dataStDev = array.stdev(id=myArray)
顺便一提,id=这个关键字参数是可选的,省略它代码也能正常工作:
// 获取 'myArray' 数组的标准差
dataStDev = array.stdev(myArray)
array.stdev()分步详解
通过一个详细的步骤来看看array.stdev()函数是如何工作的。要获取标准差,首先需要一个数组,先创建一个:
// 创建一个新的空数组
myArray = array.new_float()
这行代码创建了一个浮点数数组,引用存入myArray变量。由于未指定大小,这个数组现在是空的:
[ ]
如果此时对空数组调用array.stdev(),将会返回na,这并没有什么用。所以先用array.push()向数组中添加一些值:
// 向数组添加一些实际值
array.push(id=myArray, value=1.149)
array.push(id=myArray, value=0.238)
array.push(id=myArray, value=-2.075)
现在数组的内容变为:
[1.149, 0.238, -2.075]
有了数据,就可以来计算标准差了:
// 获取数组的标准差
dataStDev = array.stdev(id=myArray)
我们调用array.stdev(),把myArray作为参数传入。函数返回的标准差被存储在dataStDev变量中。结果是:
1.3570419628
当我们改变数组的内容时(增、删、改),标准差也可能随之改变,要获取更新后的标准差,需要再次调用array.stdev()。用array.unshift()在数组开头添加几个新元素:
// 再添加几个元素
array.unshift(id=myArray, value=0.1039)
array.unshift(id=myArray, value=-0.007)
现在数组的内容变为:
[-0.007, 0.1039, 1.149, 0.238, -2.075]
要获取新的标准差,再次调用array.stdev():
// 检索数组更新后的标准差
dataStDev := array.stdev(id=myArray)
更新后数组的标准差是:
1.0605125523
array.stdev()的用途
array.stdev()函数可以直接获取数组中所有数值的标准差。这个函数非常方便且高效,避免了手动编写循环来完成这一复杂的统计计算。
我们常常会把array.stdev()与其他数组统计函数结合使用,例如用array.avg()计算平均值,用array.range()计算范围。除了计算标准差这个核心功能外,array.stdev()没有其他特殊用途。
示例脚本
通过一个完整的脚本来看看array.stdev()的实际应用。下面的指标会把图表上所有K线的开盘价存储到一个数组中,当脚本运行到最后一根K线时,它会计算所有这些开盘价的标准差,并用一个文本标签显示出来。指标代码如下:
//@version=5
indicator(title="array.stdev() 示例脚本", overlay=true)
// 创建一个持久性的浮点数数组,用于存储所有开盘价
var openPrices = array.new_float()
// 在每根K线上,将其开盘价添加到数组
array.push(id=openPrices, value=open)
// 在最后一根K线上,用标签显示开盘价的标准差
if barstate.islast
label.new(x=bar_index, y=hl2, style=label.style_label_left,
color=#E0FFFF, textcolor=color.black, size=size.large,
text="开盘价的标准差:\n" +
str.tostring(array.stdev(id=openPrices), "0.0000"))
解析一下这段代码。脚本先用indicator()进行配置,再用array.new_float()创建一个浮点数数组,var关键字确保该数组是持久的,内容可以在K线之间保留。
在每根K线上,都用array.push()把该K线的开盘价open添加到openPrices数组中。然后用if语句和barstate.islast变量确保代码只在图表的最后一根K线上执行一次,并在该K线上用label.new()创建一个指向左方的标签。
标签的文本由两部分组成:一部分是固定的字符串”开盘价的标准差:\n”,另一部分是数组的标准差——调用array.stdev(openPrices)获取这个值,再用str.tostring()函数转换为带四位小数的文本,以便在标签上显示。
把这个脚本应用到图表时,它会显示出该图表加载周期内所有开盘价的标准差。例如在这个1小时的白银图表上:
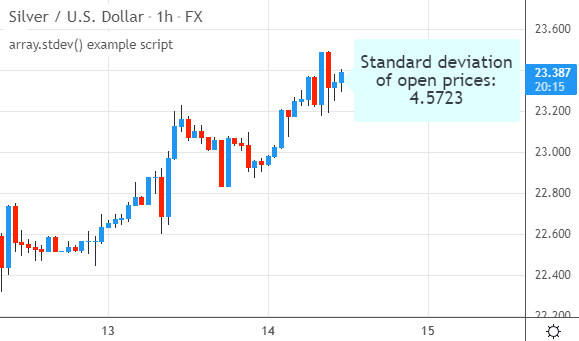
array.stdev()的特性
在统计学中,计算标准差有两种方式:一种是基于样本数据来估计总体的标准差(样本标准差);另一种是基于全部数据来计算实际的标准差(总体标准差)。array.stdev()使用的是后一种方法,即计算总体标准差。
另外,array.stdev()仅适用于整数数组和浮点数数组。如果对其他类型的数组(如标签或布尔数组)使用此函数,Pine Script会报错:cannot call ‘array.stdev’ with argument ‘id=(…)’. An argument of ‘(…)’ type was used but a ‘float[]’ is expected.
总结
array.stdev()函数返回一个整数或浮点数数组的标准差(特指总体标准差)。如果数组为空,或其中只包含na值,array.stdev()将返回na。


